



m6A甲基化测序数据分析服务
发布时间:2019-04-09 分享到:
1. 识别甲基化富集峰
通过高通量测序和生物信息分析,识别(p <10-5)甲基化富集的基因组区域。
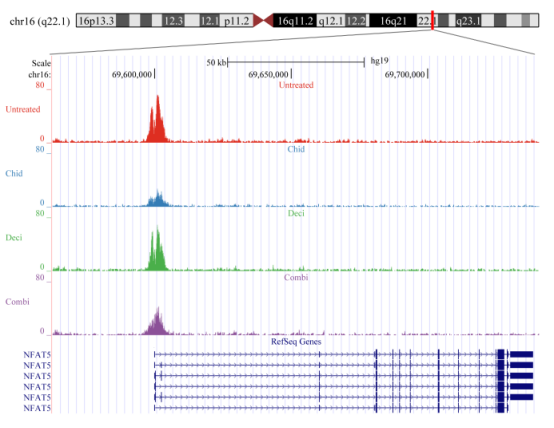
注:每个样品组做一个Input,以去除基因组背景,降低假阳性率
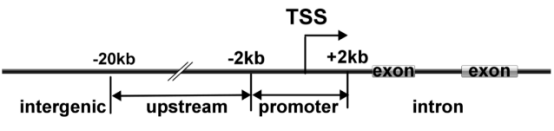
2. RNA甲基富集峰注释
通过生物信息分析利用最邻近基因对富集峰进行注释,并根据峰中点相对于已知基因的位置,将富集峰为启动子峰、上游峰、内含子峰、外显子峰、基因间峰、3UTR峰等。
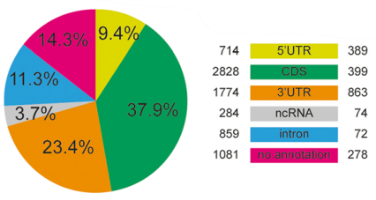
3、RNA甲基化富集峰区域的在基因组中的分布
根据注释信息,绘制富集峰在不同基因组特征上的比例图。
4、 RNA甲基化位点Motif分析
RNA上甲基化的位点,可能包含某种序列motif。RNA甲基化酶可能正是通过识别这些motif特异性进行甲基化修饰,从而完成转录后调控功能。我们成功识别了全基因组的RNA上的甲基化位点后,获取序列就能使用生物信息学的手段来搜索这些motif,从而揭示RNA甲基化修饰的机制。

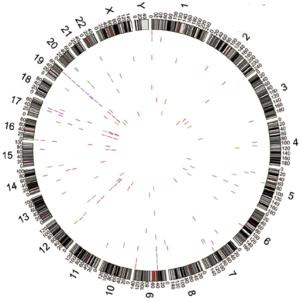
5. 差异RNA甲基化区域的识别与聚类
识别样本间的差异甲基化区,发现与特定表型或疾病相关的甲基化区域。
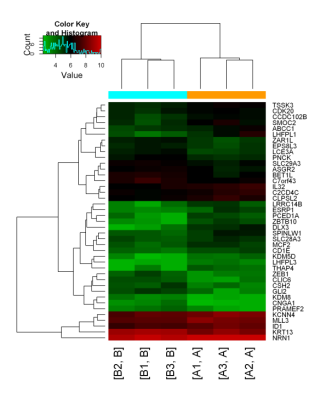
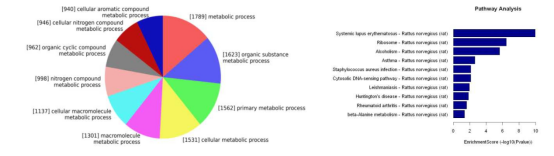
6. 差异甲基化区的GO与信号通路分析
对差异甲基化基因进行功能分类,并发现显著性富集的功能条目。
7. m6A与转录组数据的联合分析
通过联合分析,从而研究m6A对于基因转录表达、剪切等功能意义。
相关推荐
- 全基因组甲基化测序数据分析服务2019-04-09
- m6A甲基化测序数据分析服务2019-04-09
- EWAS数据分析服务2019-04-09